在云栖社区举办的在线培训中,具有十年以上系统底层开发经验的阿里云技术专家鲁振华带来了题为《Redis内存管理和优化》的精彩分享。在分享中,他以数据结构、过期机制和淘汰机制为原理,以内存分析为方法论,详细讲解了Redis在使用过程需要注意的知识和难点。
以下内容根据直播视频和幻灯片整理而成。
数据结构
通过了解数据结构,就能知道对象性能,边界条件,就自然而然知道如何恰当的使用它们,做业务时就能选到最合适的对象。
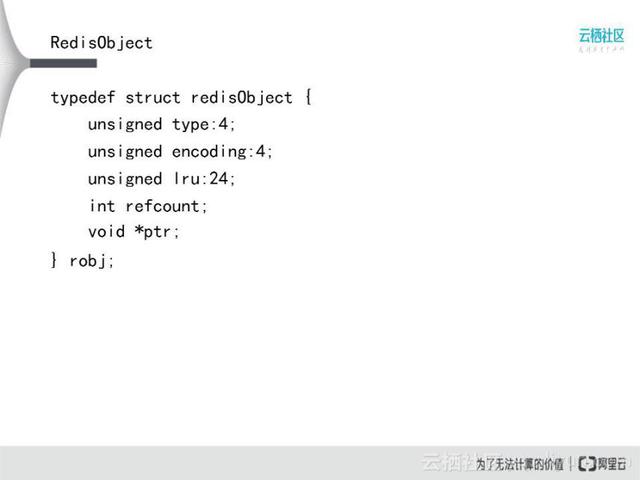
上图是Redis最基本的结构体,所有Redis对象都被封装在RedisObject中。最基本的结构代码往往是最精简的。该结构中有5个成员,type 4 比特,encoding也是4比特。从代码得知:
Redis的数据类型不超过16种,编码方式不超过16种,且类型跟编码方式不一一对应,一种类型可能有多个编码方式,数据也可以共享。
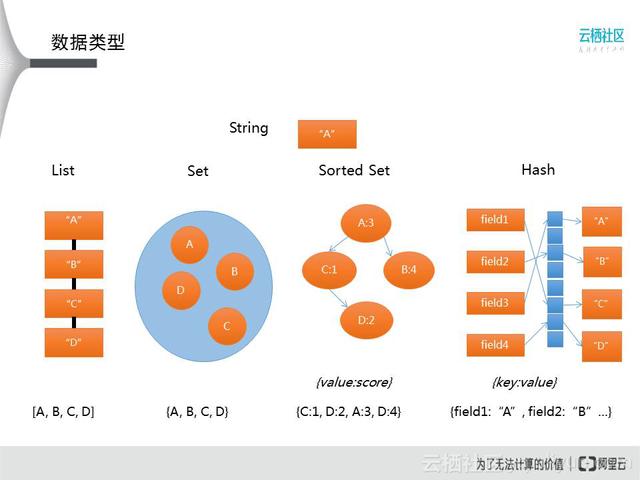
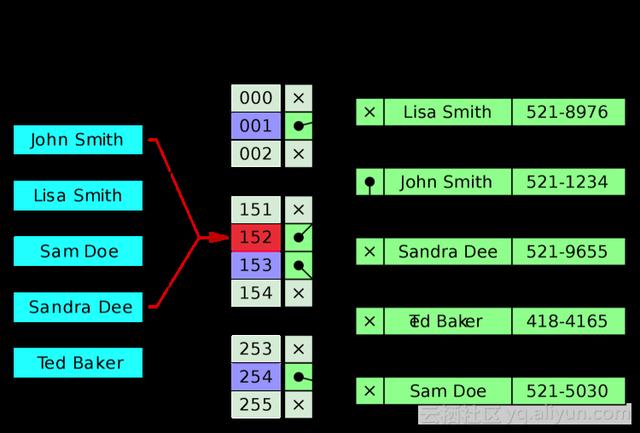
首先看Object的第一个成员type,实际上Redis里面一共有5种类型:字符串、列表、集合、有序集合、哈希,这几种方式和type的对应关系见下表。
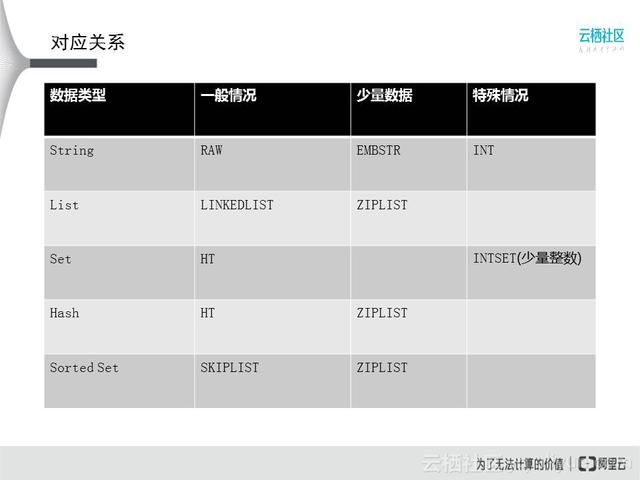
表中第二列是一般情况下数据类型所用的编码方式,字符串一般的编码方式是RAW,List对应的是链表,集合和哈希表用的是HT,SortedSet用的是SKIPLIST。很多情况下集合都是用红黑树表示,比如在C++中,所以性能复杂度都是log n,但Redis里面的Set用哈希表实现,所以读写的复杂度都是O(1)。从表中也可以看出,所有的数据类型都有不止一种编码方式。Redis在数据量小的情况下,对数据存储做了一些优化。String还有一种特殊类型,即INT类型的编码,接下来会介绍如何利用这些特性。
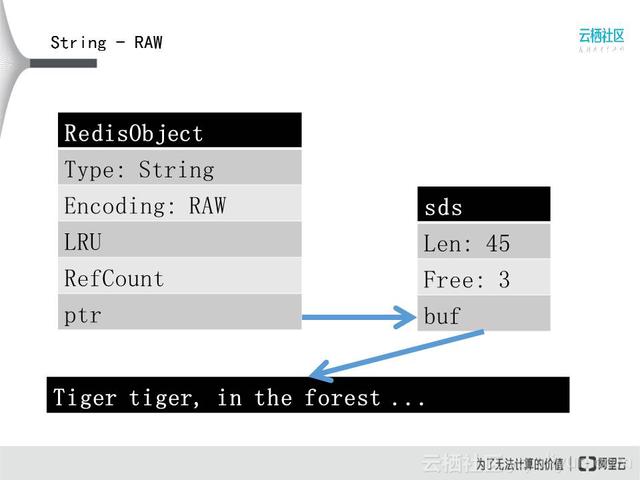
String是Redis里用的最多的一个类型,所有的Key都是字符串类型,一般情况下编码方式是RAW,它的ptr指向一个sds的数据结构,sds是Redis用来保存一般字符串的数据结构,包含Len和Free两个成员的头部。从len字段的存在可以看出,Redis的字符串不依赖结尾’�’字符的判断,可以存二进制数据,而Free字段的存在表明sds采用了某种预分配的机制。

当字符串较小,Redis里字符串长度<=39时,会用EMBSTR编码方式。在这种编码方式下,字符串跟Object在连续的内存上,省去了多次内存分配。不过当字符串增长或者改变时,不能用该种方式,需要换成第一种,所以长度限制为39。
String类型还有一种特殊的编码方式,即字符串数值是整数的时候,为特殊的INT类型编码。INT类型不需要ptr指到字符空间,而是直接用指针的值代表字符串的值,因此ptr已经不是指针。这样就省去了sds开销,其内存占用最小。实际上在Redis里,程序启动时直接创建了10000个RedisObject,代表1-10000的整型,如果LRU没有意义,后面就没有其他开销,用预先分配好的值。简单来说,整数类型的Value比普通的Value节省内存,其值为0-10000,LRU无效情况下的String Object可共享,而且一般情况下没必要强求EMBSTR。

上图是压缩列表,它相当于把所有的成员都叠在一起,没有额外的数据结构,空间占用比较小。缺点是读写的时候整个压缩列表都需要修改,所以一般在数据量小的时候才使用,一般能达到10倍的压缩比。数据量大小都可以通过配置文件更改,Hash和List的默认情况是512和64,需要利用时就对业务进行改造,可以按日期拆分,每天一个Key,也可以按数值取模,或按前缀拆分等。通过合理的拆分,充分利用压缩列表特性,压缩率可达10倍,平均为5倍。
那其他容器在普通情况下用什么样的数据结构呢?算法类的数据结构里用的最多的为哈希表。因为它的读写复杂度都是O(1),是所有数据结构里面最快的一种。Redis中的哈希表使用链地址法解决hash冲突问题,若有多个key的hash值一致,通过遍历链表的形式找到目标Key。当哈希表的负载因子过大时,冲突几率变大,其性能就会下降。Redis里面哈希表槽的数目是动态增长的,HT默认初始大小为4。当负载因子超出合理范围(0.1 – 5)时进行扩缩容(rehash),将原来哈希表里面的数值rehash,放在新的哈希表里面,也就是说同时存在两个哈希表,一旧一新。不过一次性rehash太多的Key可能导致服务长时间不可用,Redis采用渐进式rehash,分批进行。
Redis里用字典结构对Redis进行封装,主要就是两个哈希表,读写复杂度均为O(1)。DICT的读写效率最高。那什么时间进行渐进式Rehash的算法呢?每次对DICT执行添加、删除、查找或者更新操作时,除了执行指定的操作以外,还会顺带将ht[0] 哈希表在rehashidx索引上的所有键值对rehash到ht[1],并将rehashidx的值增1;直到整个ht[0]全部完成rehash后,rehashindex设为-1,释放ht[0],ht[1]置为ht[0],在ht[1]中创建一个新的空白表。
跳跃表是哈希里面用来做排序的,实现简单,算法巧妙,算法效率和平衡树一样。算法核心为,每插入一个节点,节点是随机数,第n+1层的节点数目为第n层的1/4,性能如上表所示。
过期机制
接下来介绍Redis里的过期机制。Redis作为内存数据库,和普通的关系型数据库相比,优势在于快,劣势是持久化稍差。实际上很多内存数据库都是来存一些时效性数据,比如限时优惠活动,缓存或者验证码可以采用Redis过期机制进行管理。这个时候千万不要忘记设立过期时间,若不设,只能等内存满了,一个个查看Key有没有使用。

在Redis里设过期数据很简单,直接用expire命令即可。在Key过期的时候,Redis会自动把这个Key删除。“自动”是指有一个触发时机,很容易想到用定时器。Redis为了不影响正常的读写操作,一般只会在必要或CPU空闲的时候做过期清理的动作;必要的时候即访问Key的时候,CPU空闲的时候具体分为两个,一是一次事件循环结束,进入事件侦听前,二是系统空闲时做后台定期任务。且第二个是有时间限制的。时间限制为25%的CPU时间。

Redis后台清理任务默认1秒钟执行10次,也就是100ms。相当于若没有其他操作,全都用来做后台任务,后台任务如果把CPU占满的话,一次可以执行100ms。25%的限制表示,后台任务里面,100ms里有25ms可以做过期Key清理,还有一些其他Redis管理方面的任务要做。

过期Key清理算法比较简单。首先,依次遍历所有db;然后,从db中随机取20个Key,判断是否过期,若过期,则逐出;若有5个以上Key过期,则重复上述步骤,否则遍历下一个db;在清理过程中,若达到了时间限制,超过了25ms,则退出清理过程。
总结一下算法的特点:
(1)这是一个基于概率的简单算法,假设抽出的样本能够代表整个Key空间(如果运气不好,有20个Key没过期,刚好取到这20个。算法基础为在CPU允许的时间内一直清理,一直清理到过期Key占整个db中Key的25%以下)。
(2)单次运行时间有25% CPU时间的限制。
(3)Redis持续清理过期的数据,直至将要过期的Key的百分比降到了25%以下。
(4)长期来看,任何给定的时刻已经过期但仍占据着内存空间的Key的量,最多为每秒的写操作量除以4。因为Redis最大的特色就是高效,所以会牺牲一些无关紧要的部分。
那么在实际中怎样更好地发挥Key呢?首先,淘汰过程以Key为单位,如果有大Key存在,有可能删除耗时太长,从而导致长时间服务不可用。其次,可以调高HZ参数,从而可以提升淘汰过期Key的频率,即删除的更加及时;相应的,每次淘汰最大时间限制将减少,可使系统响应时间变快;在一般情况下并不能降低过期Key所占比率;另外,会导致空闲时CPU占用率提高。不过,一般情况下可用默认值,不需要调整。
淘汰机制
机器的内存是有限的,当Redis的内存超了允许的最大内存,Redis会按照设定的淘汰策略删掉超出部分的内容。在进行淘汰时,先判断是否设置了最大允许内存(server.maxmemory);若是,会调用函数freeMemoryIfNeeded,再判断使用内存是否超出最大内存限制;若是,就按照设置的淘汰策略淘汰Key,直到使用内存小于最大内存。

可以设置不同的淘汰策略决定删除的方法。Redis默认有6种淘汰策略,如上图所示。前三种都是从已经设置过期时间的Key中删除。Key是临时数据,若设了过期时间,相比于普通数据,优先级会低一些。这里要注意,lru会影响前面所讲的整数对象的共享。
淘汰算法
淘汰算法的步骤分为五步:首先,依次遍历所有db;然后,按照设置的淘汰策略挑选一个Key进行淘汰;若策略是lru或ttl,采用近似算法,随机取n个样本(默认为5,可配置),从中选出最佳值;遍历完后,计算当前使用内存量是否超过允许值;若是,则继续步骤1。
因为大部分的操作都是以Key为单位,若一个容器对象很大,对整个Key操作,或直接删除Key耗时过长,从而导致其他命令长时间内没法响应到。另外,写入大Key导致内存超出太多,下次淘汰就需要淘汰很多内存。比如说最大内存是1G,写1G内存时发现最大内存没有超,但是若再写入一个5G的数据,等下一个命令来,发现Redis里面有6G数据,说明有5G的数据要去删除,那么删除时,不会一下就取到5G的数值,很有可能会把其他所有的Key都删除之后,发现还不够,然后再删除那5G的数据。还有一个情况,内存100%且无Key可淘汰时,这些命令全都不允许再操作了。
内存分析
内存分析能提取业务特点,了解业务瓶颈,发现业务Bug。比如一些用户说他们的Key并不多,但是内存却已满,分析后才发现,一个List有16G,相当于把售卖的数据都放到了同一个Key里面。业务量不多的时候没问题,业务量增加的时候,Key就已经很大了,说明当前的代码已经远远跟不上业务的发展。

内存分析方法有两种,一种在线,一种离线。一般采用离线方法,离线内存分析是把Redis的数据存下来,放到本地,不会有风险,数据可以任意操作,主要分为3步:一是生成rdb文件(bgsave),二是生成内存快照,三是分析内存快照。每一步都很简单,生成内存快照会用到一个开源的工具,Redis-rdb-tools,用来做rdb文件的分析。命令为db -c memory dump.rdb > memory.csv。生成的内存快照为csv格式,包含:
Database:数据库ID
Type:数据类型
Key:
size_in_bytes:理论内存值(比实际略低)
Encoding:编码方式
num_elements:成员个数
len_largest_element:最大成员长度
其中每一个Key都有六列数据,表明属于第几号数据库,这里要注意理论内存值,会比实际略低。程序员可以将生成后的快照导入到数据库,可以用sqlite,然后进行数据分析,这里简单列举几条。
查询Key个数:sqlite> select count(*) from memory;
查询总的内存占用:sqlite> select sum(size_in_bytes) from memory;
查询内存占用最高的10个Key:sqlite> select * from memory order by size_in_bytes desc limit 10;
查询成员个数1000个以上的list:sqlite> select * from memory where type='list' and num_elements > 1000 ;
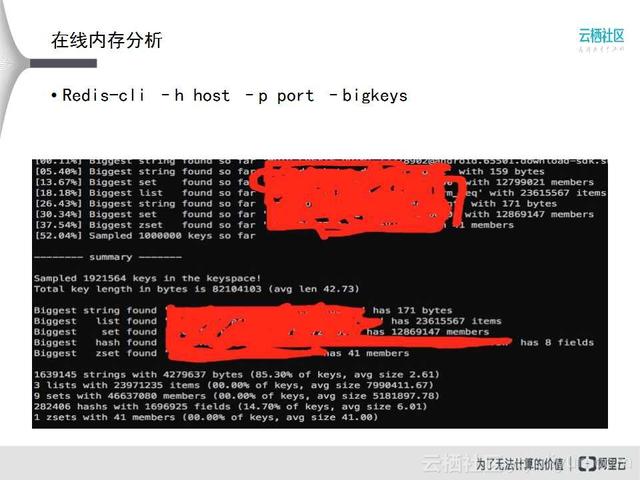
接下来是在线内存分析,这里以简单的Redis-cli为例,有一个-bigKeys的选项,可以把每种类型Key的最大Key找出来。
在这里再分享两个其他的内存分析问题。有时候Redis产品可能并没有多少东西,内存却满了,从而排查出来是其他方面的内存占用。一个可能是client占用内存的关系,因为用rdb分析的时候没有client,线上的很多连接都会带着一个很长的命令,Redis里面就会有缓存,dict rehash也会占用一些内存。内存分析时发现有一些哈希表的内存占据特别大,因为有些Key很少被访问,导致rehash被很少触发,中间缓存的表会一直删不掉。这里可以用一个脚本访问触发rehash,看内存是否变化,把表删掉即可。
最佳实践
最佳实践就是分享一下平时遇到的一些好案例,或者从前面的原理导出的一些结论。首先,最重要的就是选择正确的数据类型,主要以满足业务,性能和场景为优先考量。一般数据量不大的业务,没必要花很大的精力;但是对一些主要业务,就需要做比较细致的优化。如STRING类型对象可以考虑使用整数,如果是浮点型,就改成整数,Id等的值可以考虑用整数而不是字符串,小整数多的时候考虑使用LRU无关逐出策略等。对于数据量大,比较重要,需要做深入优化业务,还可以充分利用压缩列表,平均来说有5倍的压缩比。
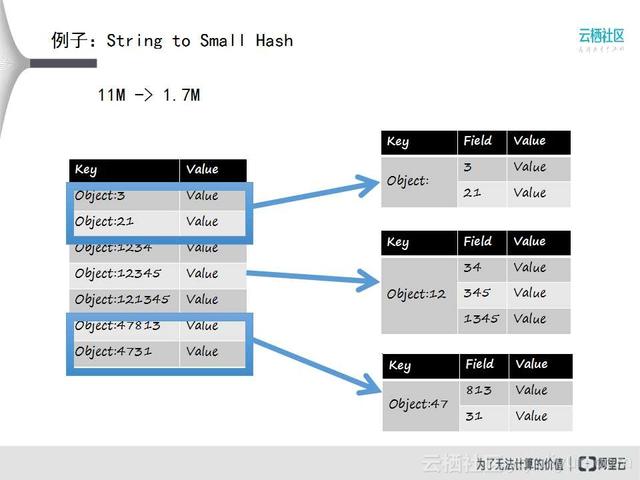
这里举个官网上的例子,在存Key - Value的时候,以object后面加一个整数作为ID,整个数据库里可能都是这种类型的数据,量又特别大,想对它优化的时候,比较通用的优化方法就是取模,相同前缀的Key单独做hash。整个db空间相当于一个大的哈希表,这样就把本来分配给整个db空间的Key,按照不同的前缀分成小的哈希表,每个哈希表里面保证数据比较小,那这个哈希表就会用压缩列表来保存。
Redis里其实有7种数据类型,另外2种是普通的String,独立出来用于特定场合,它是效率非常高且有用的一种方式。

第一个是位图Bitmap,它存储起来实际上就是字符串,最大可以是512M,当用一些读写的位操作函数操作时,位操作很快。其原理是,若统计一个网站的UV,用来访问的用户的ID做标识。其好处是节省空间。如果按传统的集合方式实现,则内存占用大,且难以合并。如果每天的用户访问都做了集合,那么统计一周内的访问,做集合的并集操作,比较占时间。而用bitmap只需将每天的字符串按位与,计算较快。比如要统计用户每天有没有访问网站,1000万个用户实际上只需要430M,用集合会很大。若统计UV,一亿两千八百万用户做位操作基本上也是几百毫秒。 Bitmap需要注意的问题是,字符串的最大长度是用户的ID指定,用户的ID是多少,就把bitmap的相应位设为1,因此如果ID取的很大,而用户量很少,Bitmap很稀疏的话,相比集合并不能体现其优势。而且大的bit位一次分配会导致setbit时间过长。那么,需要合理的进行bit位的压缩,可以用相对值不用绝对值,按位分开成多个Bitmap,每10000个用户单独用一个bitmap,存相对值;再或者用哈希函数映射成定长的ID如64位等。
第二是HyperLogLog,它是一个算法,和日志没关系,用于计数统计,操作很快,最大空间占用12K,可以记2^64个数据,误差只有0.81%。也就是说,要追求准确,就用Bitmap,但是有些业务允许有一些误差,可以使用HyperLogLog。HyperLogLog就是用来统计位有没有记成1,不管IP是多少,只要12K 的内存就够了。如果用集合,一百万个IP,64字节,一年的数据可能就要5.4G,1亿个IP,一年就要540G,HyperLogLog只要4M就可以。
https://yq.aliyun.com/articles/67122