阅读目录(Content)
-
一、配置mysql主从模式的原因
-
二、Mysql主从复制的原理
-
三、Mysql主从复制的过程
-
主从复制详细过程
-
Mysql主从复制过程的图形表示
-
四、MySQL支持的复制类型与MySQL复制应用类型
-
MySQL支持的复制类型
-
MySQL复制应用类型
-
五、MySQL(主从复制)集群配置过程
-
主节点配置(server1,1.0.0.3)
-
从节点配置(1.0.0.5=udzyh1、1.0.0.6=udzyh2)
-
连接
-
开启主从复制
-
六、Replication管理和排错
接下来带大家感受一下MySQL集群!其实什么是MySQL集群?简单的说就是一群机器(服务器)的集合,它们连在一起来工作。
其实各种数据库都有自己的集群,常常的多:
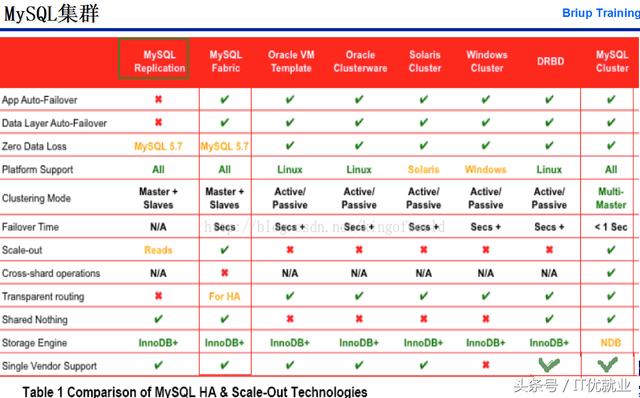
我们要学习的就是MySQL Replication
一、配置mysql主从模式的原因
1)Mysql内建的复制功能是构建大型、高性能应用程序的基础。在实际企业应用环境当中,单台mysql数据库是不足以满足日后业务需求的。
譬如当服务器发生故障,而没有备份服务器来提供服务时,业务就必须得停止,这样会对企业带来巨大的损失。
2)为了提高数据库服务器的稳定性,加快数据处理的效率,保护数据免受意外的损失,我们采用mysql的主从复制方式,分离对数据库的查询和更新操作,使用从服务器上备份的数据保证来数据的安全性和稳定性。
二、Mysql主从复制的原理
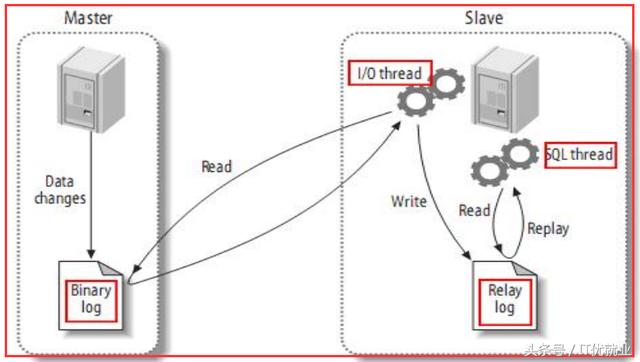
1)MySQL 的 Replication 是一个异步的复制过程,从一个 MySQL instace(我们称之为 Master)复制到另一个MySQL instance(我们称之 Slave)。
在 Master 与 Slave 之间的实现整个复制过程主要由三个线程来完成,其中两个线程(Sql 线程和IO 线程)在 Slave 端,另外一个线程(IO 线程)在 Master 端。
2)在执行这个主从复制之前,首先必须打开 Master 端的Binary Log(MySQL-bin.xxxxxx)功能,否则无法实现。
在启动 MySQL Server 的过程中使用“log-bin” 参数选项
在 my.cnf 配置文件中的 MySQLd 参数组中增加“log-bin” 参数项
三、Mysql主从复制的过程
3.1、主从复制详细过程
1) Slave 上面的IO 线程连接上 Master,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容。
2) Master 接收到来自 Slave 的 IO 线程的请求后,通过负责复制的 IO 线程根据请求信息读取指定日志指定位置之后的日志信息,返回给 Slave 端的 IO 线程。
返回信息中除了日志所包含的信息之外,还包括本次返回的信息在 Master 端的 Binary Log 文件的名称以及在 BinaryLog 中的位置。
3)Slave 的 IO 线程接收到信息后,将接收到的日志内容依次写入到 Slave 端的RelayLog (中继日志文件)文件(MySQL-relay-bin.xxxxxx)的最末端,并将读取到的Master 端的bin-log 的文件名和位置记录到master-info 文件中,
以便在下一次读取的时候能够清楚的告诉Master“我需要从某个bin-log 的哪个位置开始往后的日志内容,请发给我” 。
4)Slave 的 SQL 线程检测到 Relay Log 中新增加了内容后,会马上解析该 Log 文件中的内容成为在 Master 端真实执行时候的那些可执行的 Query 语句,并在自身执行这些 Query。
这样,实际上就是在 Master 端和 Slave 端执行了同样的 Query,所以两端的数据是完全一样的。
3.2、Mysql主从复制过程的图形表示
四、MySQL支持的复制类型与MySQL复制应用类型
4.1、MySQL支持的复制类型
1)基于语句的复制statement: 在主服务器上执行的SQL语句,在从服务器上执行同样的语句。MySQL默认采用基于语句的复制,效率比较高。一旦发现没法精确复制时,会自动选着基于行的复制。
2)基于行的复制row:把改变的内容复制过去,而不是把命令在从服务器上执行一遍. 从mysql5.0开始支持
3)混合类型的复制mixed: 默认采用基于语句的复制,一旦发现基于语句的无法精确的复制时,就会采用基于行的复制。
4.2、MySQL复制应用类型
1)数据分布 (Data distribution )
2)负载平衡(load balancing)
3)读写分离(split reading and writting)
4)高可用性和容错性 (High availability and failover )
五、MySQL(主从复制)集群配置过程
环境:
首先我虚拟机中安装了三台ubuntu操作系统:
ubuntu的server版:1.0.0.3==server1
ubuntu的desktop版(两台):1.0.0.5=udzyh1。1.0.0.6=udzyh2
注意搭建MySQL集群的时候,MySQL的版本尽量一致,大版本必须一致。(本人使用5.7.19)
5.1、主节点配置(server1,1.0.0.3)
1)首先进入到MySQL的配置文件中去
sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf
2)修改、保存退出
[client]
[mysqld]
#bind-address=0.0.0.0
server-id=11
log-bin=mysql-bin-11
binlog-format=row
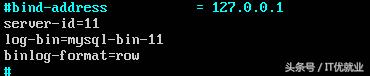
3)重启MySQL服务 sudo service mysql restart
5.2、从节点配置(1.0.0.5=udzyh1、1.0.0.6=udzyh2)
注意:所有从节点的配置都一模一样(主从复制,只能有一个主节点,可以用n多个从节点)
1)首先进入到MySQL的配置文件中去
sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf
2)修改、保存退出
[mysqld]
#bind....
server-id=12
relay-log=mysql-relay-12

3)重启MySQL服务 sudo service mysql restart
5.3、连接
1)在主节点的MySQL终端执行:
grant replication slave,replication client on *.* to 'zyh'@'%' identified by '123456';(在主节点创建一个用户)
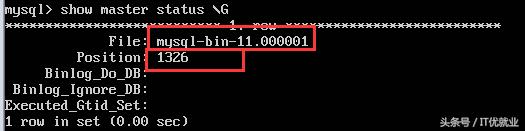
2)查看主节点的二进制文件名和插入位置
show master stauts G
3)在从节点的MySQL终端执行
change master to
master_host='1.0.0.3',(这里最好使用ip,其实写主机的也是可以的,但是一个局域网内主机名很多相同的话,会找不到)
master_port=3306,
master_user='zyh',
master_password='123456',
master_log_file='mysql-bin-11.000002',
master_log_pos=1326;
注意:n多个从节点都是相同的配置
3)查看从节点的状态
show slave status G
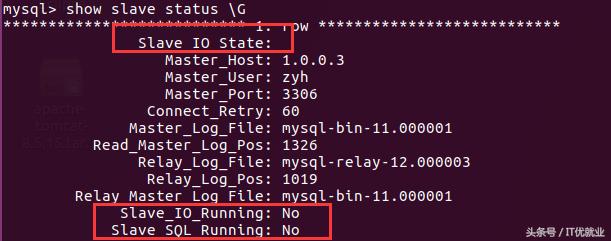
5.4、开启主从复制
start slave
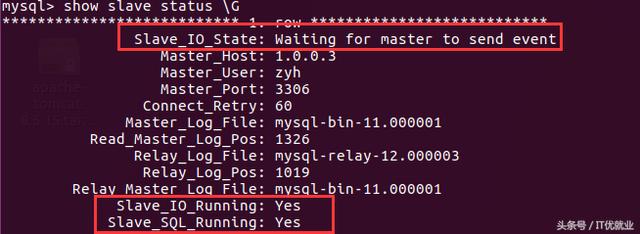
1)查看所有数据库
在主节点中:
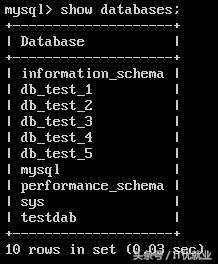
在从节点中:
1)
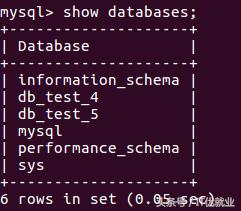
2)
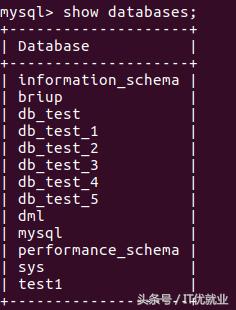
2)主节点创建一个数据库db_love在查看其它两个从节点,你会发现惊喜
六、Replication管理和排错
1)show master status ; 查看master的状态, 尤其是当前的日志及位置
2)show slave status; 查看slave的状态.
3)reset slave ; 重置slave状态,用于删除SLAVE数据库的relaylog日志文件,并重新启用新的relaylog文件.会忘记 主从关系,它删除master.info文件和relay-log.info 文件
4)start slave ; 启动slave 状态(开始监听msater的变化)
5)stop slave; 暂停slave状态;
6)set global sql_slave_skip_counter = n 跳过导致复制终止的n个事件,仅在slave线程没运行的状况下使用
转自:博客园